Meldingen van computerproblemen zijn talrijk. Er draaien nog veel systemen die moeite hebben om storingen of hacken te voorkomen. Omdat we ze niet meer kunnen missen zullen we ze snel moeten verbeteren. Dat kan gelukkig middels mijn snelle gestructureerde methode gebaseerd op moderne vrij te gebruiken technieken. De oude programma’s worden dan van een nieuwe betrouwbare en veilige laag voorzien. Aan de slag dus.
Wat is er aan de hand
Er is de laatste tijd een toename van berichten in de Media over computer storingen, gelekte gegevens, en gevallen van ransomware. Het lijkt wel duidelijk dat computersystemen vaker het doelwit zijn van criminelen. Gaat het hier om wat oudere, misschien verwaarloosde systemen? Is dit het topje van de ijsberg en volgen er meer meldingen?
Welke problemen geeft dat
We zijn afhankelijk van onze computersystemen, bij uitval ligt vaak een groot gedeelte van de bedrijfsvoering stil. Als slachtoffer van ransomware ontstaat het dilemma van losgeld betalen. Bij gestolen gegevens maak je kans voor nalatigheid een boete te krijgen. Men kan ook de stiekem verkregen gegevens gebruiken voor een ander doel zonder dat jij het direct in de gaten hebt. De aandacht in de Media is geen goede reclame voor je bedrijf.
Niet alleen bedrijven zijn afhankelijk en kwetsbaar, ook voor instellingen ten behoeve van onze maatschappij zijn goed functionerende en beveiligde computersystemen onontbeerlijk. Diverse voorbeelden zijn de laatste tijd in de Media geweest.
Oorzaken vanuit het verleden

Als halfautomatisch systeem ontworpen
Het ontwerp ging vroeger uit van zoveel mogelijk geautomatiseerde processen. In normale gevallen werkt dat, maar bij een lichte verstoring is een handmatige correctie gebruikelijk. Tegenwoordig merken we dat toegang voor handmatig ingrijpen gebruikt wordt voor het aanvallen van een systeem. Eenmaal toegang gekregen heeft men vaak (te) grote bevoegdheden en is er lastig te traceren wat voor acties er zijn ondernomen. Een goed bedoelende specialist kan onbedoeld het systeem ondermijnen, die andere specialist, de hacker, doet het bewust. Soms is de ondermijning direct merkbaar, maar het kan ook sluimerend aanwezig zijn, eventueel ter voorbereiding op iets ergers.
Meerdere disciplines zijn verantwoordelijk
Wat vroeger ook een rol speelde: er waren twee disciplines verantwoordelijk voor een IT systeem, de ene schreef de software en de andere rolde het uit. Dat resulteerde nogal eens in incomplete gegevens bij de overdracht, bij het over te dragen programma hoort ook extra informatie zoals de voorwaarde waaronder het moet draaien, parameters die afhankelijk zijn van de omgeving waarin het gaat draaien en nog meer. Een handleiding moest uitkomst bieden. Maar het is een kunst om die te maken. Het IT systeem werd ook niet in zijn geheel overgedragen maar het was een set onderdelen, ieder met zijn eigen instructies. Installatie gaat dan bijna nooit in één keer goed, met als gevolg handmatige correcties en (te) korte testen om de goede werking te controleren. Men is (te) snel tevreden met de werking waardoor er soms vervelende subtiele fouten onopgemerkt blijven.
Toegankelijk maken van de server voor andere systemen
De systemen draaien nooit helemaal geïsoleerd, er zijn vaak gegevens van anderen systemen nodig. Bij zo’n overdracht is er meestal direct contact tussen de servers van beide systemen. Hiervoor wordt een poort open gezet, die goed beveiligd moet worden. Beveiligen betekent vooral dat je met de laatste security updates werkt. Dat gaat vaak mis. Veel bedrijven wachten te lang met het aanbrengen van die updates.
Waardevolle gegevens zijn zichtbaar aanwezig op de server van het systeem
Toegang tot de server van een systeem via de shell geeft bij die oude systemen ook zicht op de inhoud van scripts, configuratiebestanden en databestanden en meestal de mogelijkheid om het ook te wijzigen. Andere mogelijkheden zijn het stelen van gegevens en achterhalen van geheimen zoals inlog gegevens van een database.
De server van het systeem is moeilijk vervangbaar
Doordat essentiële informatie, die nergens anders staat, op de server van het systeem blijft staan, kan je de server niet zo makkelijk door een ander vervangen. Een kapotte of gegijzelde server, vereist specialistisch werk en kost tijd.
Wat kan je er aan doen?
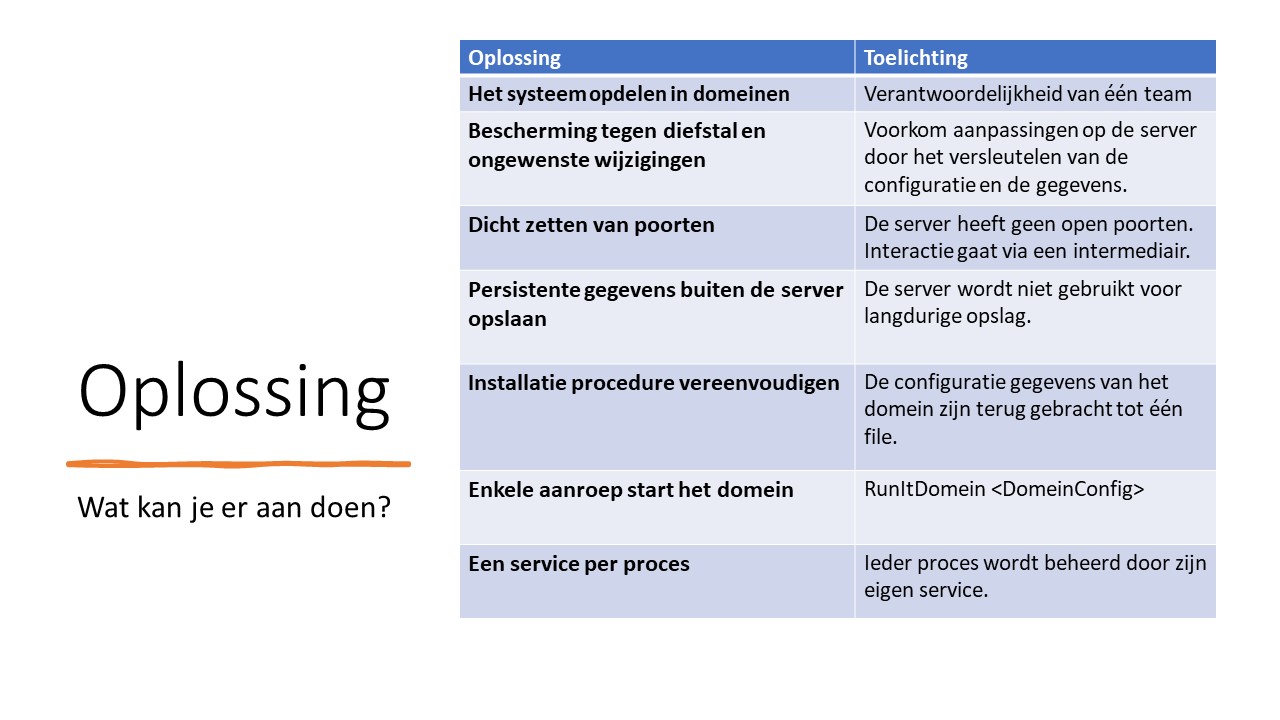
Het systeem opdelen in domeinen
Ieder domein van het systeem staat op zijn eigen server en heeft zijn eigen Git repository. Het idee is dat iedere verandering terug te vinden is in de repository. Het onderhoud op de repository gebeurt door een team met als doel dat iedere wijziging door minstens 4 geautoriseerde ogen is gecontroleerd. Als er onderdelen zijn van het systeem waar het team geen verantwoordelijkheid voor heeft dan verhuist dat stuk naar een ander domein en zal er een formele interface worden afgesproken. Verdere regels voor het opbreken kunnen van technische en organisatorische aard zijn. Ieder domein heeft zijn eigen beheer cyclus. Een nieuwe domein beschrijving ontstaat alleen als deze getest en goed bevonden is.
Bescherming tegen diefstal en ongewenste wijzigingen
Door de geëxporteerde configuratie uit Git versleuteld op de server te zetten, dwing je af dat de wijzigingen altijd via Git lopen. Dat is een bescherming tegen je zelf maar natuurlijk ook tegen een hacker. Uiteraard is het verstandig de toegang tot de server dicht te gooien. Deze tweede ring van beveiliging geeft extra bescherming.
Als er vanuit de processen waardevolle gegevens op de server worden gezet dan moeten die ook versleuteld worden. Het is echter beter om zulke gegevens, als ze buiten het proces bewaard moeten worden, op een andere plek op te slaan.
Dicht zetten van poorten
Voorkom direct contact met de server van jouw domein. Dan zijn er geen open poorten. De server valt minder op en als niemand jouw server adres gebruikt, ben je vrij om de server te vervangen door een andere. Hoe wissel je dan gegevens uit met een ander domein? Dat kan via een derde, betrouwbare partij, bijvoorbeeld een cloud provider, waar je een storage container huurt en die gebruikt om data uit te wisselen. De beveiliging en beschikbaarheid daarvan, transport (Https) en opslag (versleuteld) is in orde, beter waarschijnlijk dan je zelf kan bereiken. En wil je een event krijgen als er wat in de storage container is neergezet? Dat is mogelijk. Daar hoef je geen poort voor open te zetten.
Persistente gegevens buiten de server opslaan
Als het je ook lukt om alle persistente gegevens buiten de server op te slaan, kan je makkelijker wisselen van server. Dat kan door gebruik te maken van een storage provider, veiligheid en beschikbaarheid is dan in orde, alleen de bestaande processen moeten daar nog mee omgaan. Dat wordt opgelost door de service die het proces beheert, die zorgt dat de gegevens just in time beschikbaar zijn op het moment dat het gegevens verwerkende proces kan starten. De gepersisteerde resultaten van het proces worden na afloop verplaatst naar de storage provider.
Installatie procedure vereenvoudigen
Het domein is eenvoudiger te installeren op een server als de domeinbeschrijving maar uit één configuratiebestand bestaat. Iedere wijziging betekent een nieuwe domeinbeschrijving, met nieuwe, gewijzigde of verwijderde services.
Enkele aanroep start het domein
Het is de bedoeling om een server te hebben waar een programma draait met deze pseudo aanroep:
- runITDomein <versleutelde domeinbeschrijving>
En daarmee wordt het domein met één commando in de lucht gebracht. Hierdoor wordt het eenvoudiger een nieuwe versie van het domein te draaien. Je kunt ook met één klap de normale verwerking vervangen. Dat is te gebruiken in situaties waar een conversie nodig is voordat een nieuwe versie van het domein actief wordt.
Een service per proces
Op die domeinserver draait voor ieder proces een nooit eindigende service die het proces telkens start als de voorwaarde daarvoor geldig is.
Werkwijze
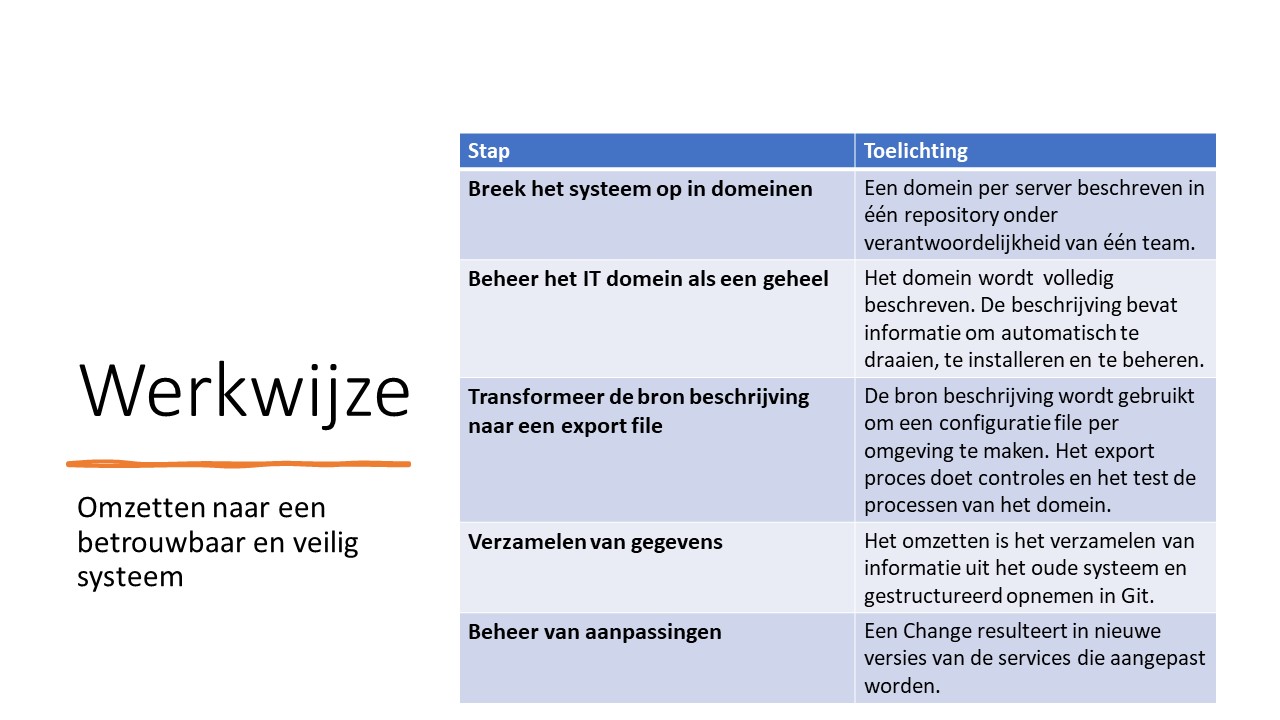
Breek het systeem op in domeinen
Het resultaat is één domein per server beschreven in één repository onder verantwoordelijkheid van één team. Let vooral op dat er geen onderdelen zijn waar een ander team voor verantwoordelijk is. Een goede indeling kan voorkomen dat een voor jou niet traceerbare wijziging, de oorzaak is van het falen van jouw systeem.
Beheer het IT domein als een geheel
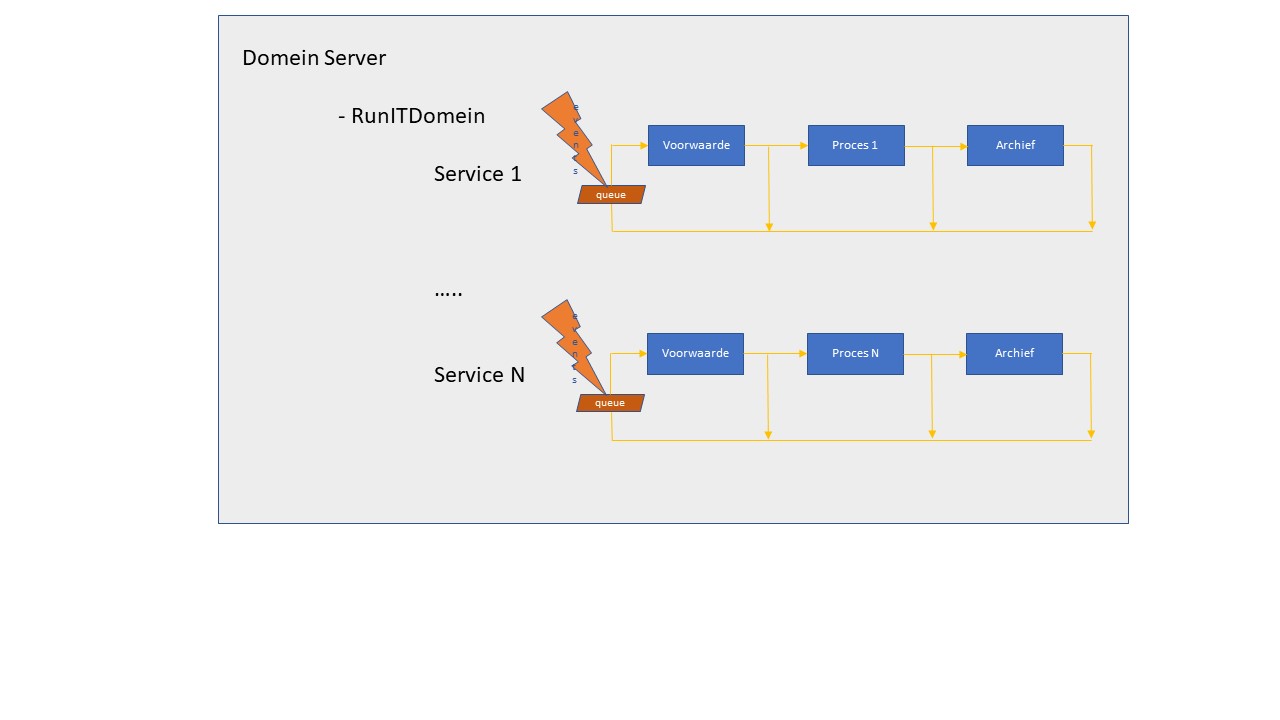
Wat is een IT domein concreet? Het bestaat uit processen die, als ze mogen en kunnen, periodiek gestart worden. Er is een service per proces die de voorwaarden in de gaten houdt en het proces dan start. Het proces zelf bestaat uit één of meerdere programma stappen en zo’n stap is een programma taak of zelf weer een flow van stappen. De stap geeft altijd een uitkomst: het is goed of fout gegaan.
In de flow kan je spelen met die uitkomst. Je hebt flows die de stappen uitvoeren totdat er eentje fout gaat of flows die uitvoeren tot er eentje goed gaat of hij voert ze gewoon allemaal uit, serieel of parallel.
De programmataak beschrijft het programma: hoe het gestart wordt, de commandline, met welke parameters en welke omgevingsvariabelen. At runtime volstaat de commandline eventueel aangevuld met de inhoud van een directory tree. De directorytree wordt dan opgebouwd voordat het programma op basis van de commandline wordt opgestart. Het garandeert dat alles te starten is: van scripts, gecompileerde programma’s met een framework tot standalone executables met eventuele shared libraries.
Het zijn dus de services die continue draaien en op de goede momenten, als alle resources aanwezig zijn en de tijd rijp is, hun proces starten. Nadat het proces gedraaid heeft moet de startvoorwaarde wel opgeheven worden. Meestal gebeurt dat in een archiveringsstap nadat het proces goed geëindigd is. De services voorkomen fouten en hebben een zelfcorrigerend karakter. Het proces doet zijn ding en geeft aan of het goed of fout is gegaan, en de service regelt de foutafhandeling, het eventuele opnieuw proberen. De services kunnen reageren op events, zoals timer events, watch events op het file systeem en op queue’s etc….
Het verwerken van data op de plek waar het afgeleverd wordt, wil nog wel eens leiden tot het archiveren van nog niet verwerkte gegevens. De service kan hier een rol spelen door de te verwerken gegevens eerst naar de plaats van verwerking te brengen en dan het proces te starten.
De service zorgt er ook voor dat de events serieel worden afgehandeld waardoor het proces niet per ongeluk parallel wordt gestart. Gewenst parallel verwerken van gegevens is echter wel mogelijk. De service is belangrijk en mist nog al eens in oude systemen.
Het IT systeem draait op een Operating System, Windows of een Unix variant en start het programma “RunITDomein <domeinbeschrijving>”. Het image van het Operating System wordt beschreven met een dockerfile.
Transformeer de bron beschrijving naar een export file
De beschrijving gaat dus volgens sterk getypeerde datastructuren. Door die formele beschrijving krijg je hulp van de IDE met intellisense en met behulp van de compiler zorgt de IDE ook voor fout detectie. De beschrijving wordt gecompileerd en uitgevoerd. Het resultaat is een versleutelde exportfile. Dat is de file die door “RunITDomein” wordt uitgevoerd.
De informatie die je oplevert gebeurt op basis van een parameter, de omgeving. Jij hebt de mogelijkheid iets anders op te leveren in de Ontwikkel omgeving dan in de Productie omgeving. Daarom vul je niet een datastructuur met een vaste waarde, maar maak je een functie die de waarde terug geeft op basis van zijn parameter. Vanwege dit mechanisme kan je ook eigen controles uitvoeren met als ultieme controle een praktijk test. Jouw IT domein wordt gecompileerd met gedeeltelijk eigen controles en eigen generatie logica.
De informatie haal je uit de gegevens van het bestaande systeem. Soms is die informatie nog niet geschikt om op te nemen: een Java of C# sourcefile is niet uitvoerbaar, die moet eerst gecompileerd worden. Dat compileren kan je doen op het moment dat jouw functie wordt aangeroepen om de informatie aan te leveren voor de service waarin deze programmataak een rol speelt.
Beheer van aanpassingen
Als je het domein gaat aanpassen, ontstaat er een tweede versie van. Want naast de actuele versie ontstaat de nieuwe versie die nog in ontwikkeling is. De sources van beide versies moeten onderhouden kunnen worden. Daarvoor wordt er in Git een Change opgenomen. Als er vanwege de Change een service veranderd moet worden (nieuw, gewijzigd of verwijderd) dan wordt daar een nieuwe versie van gemaakt en die versie wordt gekoppeld aan de Change. De Change doorloopt een levensloop van Ontwikkeling via extra omgevingen uiteindelijk naar Productie. Door de koppeling met de versie weet de export functie in Git welke versies van de services in de beschrijving van de desbetreffende omgevingen komen.
Verzamelen, rangschikken en vastleggen
Echt nieuwe dingen ga je niet doen. Een complete beschrijving maken betekent verzamelen van wat er al is, dat rangschikken en vastleggen. En wat je tijdens het ontwikkel proces met de hand deed ga je nu geautomatiseerd doen. Daarmee leg je al die gefragmenteerde kennis gestructureerd op één plek vast. In Git natuurlijk, waardoor je alle wijzigingen kan traceren.
De datastructuren van een IT domein op een rijtje
-
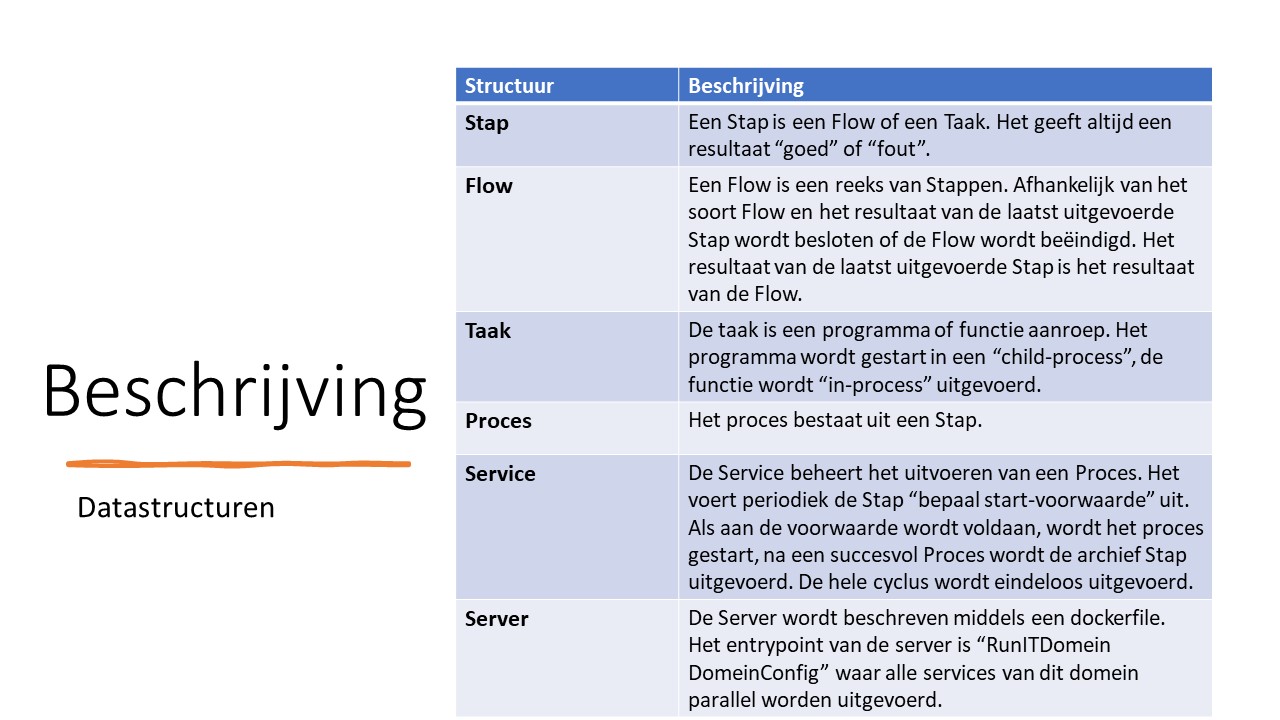
Stap
Met een stap beschrijf je een programma flow of een enkele taak of combinaties daarvan. Dit is de definitie in woorden:
Een Stap is een Flow of Taak
Een Flow is een lijst van Stappen (list) Een Taak is een Programma met parameters Een Stap geeft altijd een resultaat van "goed" of "fout" -
Flow
Een flow is een lijst van stappen. De stappen worden in volgorde uitgevoerd behalve bij de Parallel Flow.
Bij de Unconditional Flow worden alle stappen uitgevoerd.
Bij de UntilOk Flow stopt het uitvoeren na de eerste Stap die goed gaat.
Bij de UntilError Flow stopt de uitvoering na de eerste Stap die fout gaat.
Bij de Parallel Flow worden alle Stappen tegelijk gestart. -
Taak
Een taak is een programma of script of dll-aanroep -
Proces
Een Proces bestaat uit een Stap.
Die Stap is een enkele Taak of een Flow die de verwerking van het Proces doet. -
Voorwaarde
Dit is een Stap die bepaalt of een Proces uitgevoerd kan worden -
Archivering (Archief Stap)
De Archivering is de Stap ter afsluiting van het Proces om de Voorwaarde hiervan op te heffen.
Ter verduidelijking: als de voorwaarde het bestaan van path “input/mutatie123.txt” is dan verplaatst de Archivering deze bijvoorbeeld naar “archief/mutatie123.txt”.
Hiermee voorkom je dat het bestand twee keer wordt verwerkt. -
Service
Een Service verzorgt de uitvoering van een Proces op basis van de Voorwaarde De flow beschrijving is: UntilErrorFlow(Voorwaarde;UntilErrorFlow(Proces; Archivering)) Als de Voorwaarde succesvol is uitgevoerd, wordt het Proces uitgevoerd.
Als het Proces succesvol is uitgevoerd wordt de Archivering uitgevoerd.
De Service doet dit repeterend met een op te geven interval maar kan ook reageren op events, voor een snellere reactie. -
Test
De Test is een Flow bestaande uit 3 stappen: TestInit, Service, en TestOpruimen.
De flow beschrijving is: UnconditionalFlow(UntilErrorFlow(TestInit;Service);TestOpruimen)
En gewoon beschreven: TestInit wordt gedraaid, als dat goed is gegaan dan draait de Service en ongeacht de eerdere resultaten draait TestOpruimen. -
De Server
De server wordt beschreven met een dockerfile
In die dockerfile staat het Operating System en alle noodzakelijke software beschreven.
Het entrypoint is het programma runITdomein met de domeinbeschrijving als parameter.
Samenvatting

Er zullen heel wat IT systemen zijn die hun werk naar behoren doen maar daarbij soms een handmatig zetje nodig hebben. Daarvoor is toegang nodig op de server. De oudere systemen zijn niet altijd bijgewerkt met de laatste software updates, dat maakt ze kwetsbaar. Men durft niet goed, bang dat het systeem omvalt. De mensen die het gemaakt hebben zijn weg, de documentatie is niet betrouwbaar en het is lastig te testen. Aanvallers hebben op de server vrij spel, soms zijn ze maanden actief voordat iemand iets in de gaten heeft.
Als je zonder angst verder wil met zo’n systeem dan zal je alles wat nodig is om het systeem te ontwikkelen, te testen en te draaien, moeten verzamelen en gestructureerd vastleggen in een Git repository. Daarmee komt automatisch testen binnen bereik, kan je de processen beter beheersen en wordt het mogelijk om gebruik te maken van nieuwe technieken zonder het bestaande helemaal om te gooien. Als bonus heb je een fantastisch gedocumenteerd systeem, het nageslacht zal dankbaar zijn.
Het is logisch dat er tegenaan gehikt wordt. Het klinkt als veel werk. Toch kan dat meevallen. Natuurlijk zal je het systeem moeten doorgronden en de juiste versies van de software opzoeken. Dat kan je echter voor een groot gedeelte op de server terugvinden, alleen bij gecompileerde programma’s zal je de juiste source ergens anders moeten vinden. En daarbij komt de angst dat veel van de scripts en programma’s veranderd moeten worden. Dat kan erg meevallen als je het slim aanpakt.
Ik heb een methodiek ontwikkeld waarbij je gebruik maakt van de compiler in combinatie met de IDE om de gegevens foutvrij vast te leggen. Intellisense helpt tijdens het invoeren en geeft de fouten aan. Je wordt gestopt als de broncode niet door de compiler komt. Je kunt daar boven op ook je eigen fout detectie toevoegen voordat jouw service getest wordt.
Niet alleen fout detectie is mogelijk, je bent degene die de datastructuren vult. Dat betekent dat je bij veel voorkomende patronen eenvoudiger data structuren kan gebruiken en van daaruit de standaard structuren vult. De hoeveelheid gegevens die je vastlegt wordt daardoor minder, de kans om fouten te maken kleiner en het geheel wordt leesbaarder.
De wijzigingen die je in het systeem wil maken zoals de versleuteling van scripts en data en het gebruik van storage containers kan in de service geconfigureerd worden. Zo wordt de bestaande software ontzien.
De tools zijn dus zeer geavanceerd, gratis, worden goed onderhouden en veel gebruikt. Met mijn definities kan je ieder systeem vastleggen maar ik heb rekening gehouden met uitbreidingen op de definities als dat nodig zou zijn. Daarvoor hoef je niet al het eerdere werk aan te passen.
Pak het zelf aan, met een team uiteraard. Voor veiligheid en betrouwbaarheid is het vier ogen principe belangrijk, laat dus altijd iemand controleren. Ik kan je op weg helpen!